


Dave Johnson (The Roller Weblogger) has written a very nice blog How Rome Works describing (as the title says) how Rome works. With his permission we are adding it to Rome documentation.
I spent some time exploring the new Rome feed parser for Java and trying to understand how it works. Along the way, I put together the following class diagram and notes on the parsing process. I provide some pointers into the Rome 0.4 Javadocs.
You don't need to know this stuff to use Rome, but it you are interested in internals you might find it interesting.
Rome is based around an idealized and abstract model of a Newsfeed or "Syndication Feed." Rome can parse any format of Newsfeed, including RSS variants and Atom, into this model. Rome can convert from model representation to any of the same Newfeed output formats.
Internally, Rome defines intermediate object models for specific Newsfeed formats, or "Wire Feed" formats, including both Atom and all RSS variants. For each format, there is a separate JDOM based parser class that parses XML into an intermediate model. Rome provides "converters" to convert between the intermediate Wire Feed models and the idealized Syndication Feed model.
Rome makes no attempt at Pilgrim-style liberal XML parsing. If a Newsfeed is not valid XML, then Rome will fail. Perhaps, as Kevin Burton suggests, parsing errors in Newsfeeds can and should be corrected. Kevin suggests that, when the parse fails, you can correct the problem and parse again. (BTW, I have some sample code that shows how to do this, but it only works with Xerces - Crimsom's SAXParserException does not have reliable error line and column numbers.)
Here is what happens during Rome Newsfeed parsing:
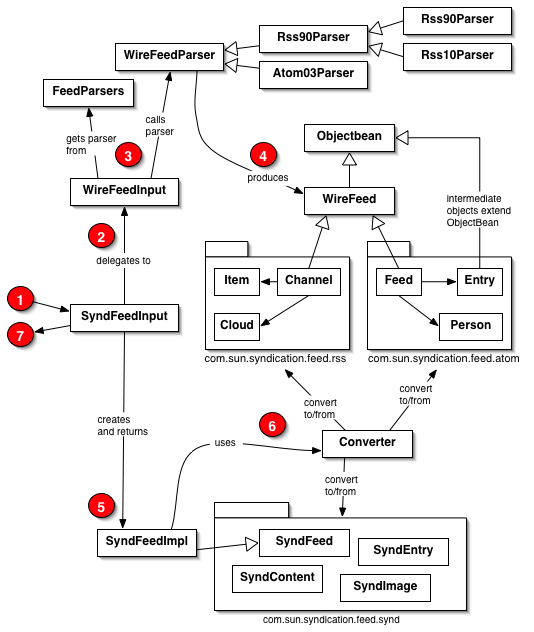
URL feedUrl = new URL("file:blogging-roller.rss");
SyndFeedInput input = new SyndFeedInput();
SyndFeed feed = input.build(new InputStreamReader(feedUrl.openStream()));
Rome supports Newsfeed extension modules for all formats that also support modules: RSS 1.0, RSS 2.0, and Atom. Standard modules such as Dublic Core and Syndication are supported and you can define your own custom modules too.
Rome also supports Newsfeed output and for each Newsfeed format provides a "generator" class that can take a Syndication Feed model and produce from it Newsfeed XML.
I've linked to a number of the Rome 0.4 Tutorials, here is the full list from the Rome Wiki: